Integration into Jira Software (agile Gantt-Charting)
- Frank Polscheit (PSIT)
Jira Software is supported as well on displaying epics, sprints and backlogs (SCRUM) or as KANBAN view grouping related issue status'. In both cases, you have to select your related agile board as shown below. Be aware of Atlassian's internal object model: a sprint is no longer just a custom field belonging to an issue as it was in older times of "Greenhopper" (original name of "JIRA Agile" before rebranding). Now, a sprint belongs to an agile view and an issue can be assigned to a sprint of an agile board. Thus, having multiple agile boards, an issue can belong to different sprints having a 1:n relationship and not a 1:1 as often assumed.
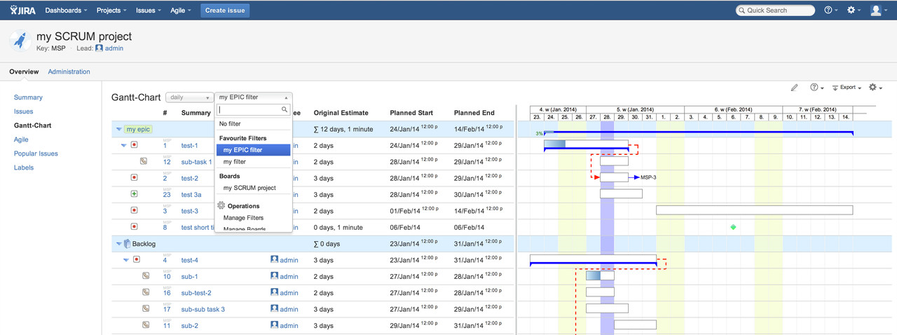
Displaying a Gantt-Chart using an agile board
If you select an agile board (SCRUM or KANBAN) instead of a JIRA filter, you will get a Gantt-Chart as displayed below being grouped by epics, sprints and backlog or based on its Kanban status':
- Epics
- epic
- epic
- Sprint(s)
- issue
- sub-issue
- sub-issue
- sub-sub-issue (unlimited level of issue hierarchy, whereas JIRA only supports issues and sub-issues natively)
- issue
- issue
- Backlog
- issue
- sub-issue
- sub-issue
- issue
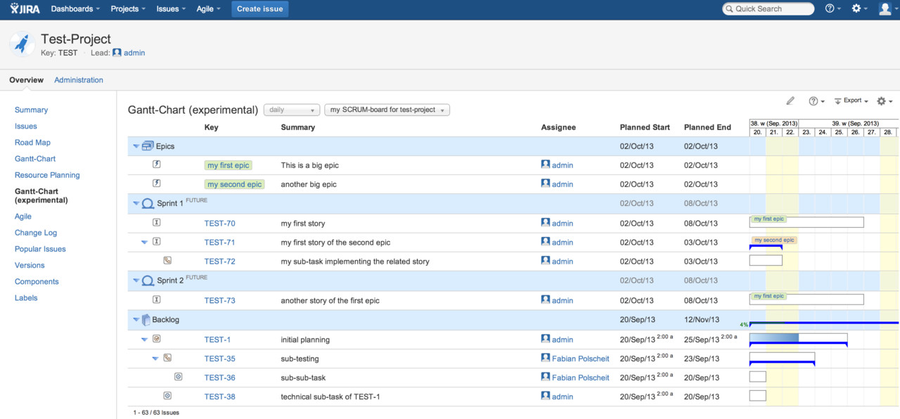
Displaying a Gantt-Chart with grouping by epics to support product owners etc.
Alternatively, you create a new JIRA filter having a JQL statement containing "ORDER BY epic-names". Depending on your language you have to translate/adjust "epic-names" (you cannot use epic links as JIRA Agile does not support ordering by this) within the order-by clause. This special order-by clause will force a grouping by epics. Within each epic row, aggregated sums of estimations will be displayed and the epic's planned start/end date will be automatically adjusted to fit to min/max of related issues.
- epic-1
- issue
- sub-issue
- sub-issue (unlimited level of issue hierarchy, whereas JIRA only supports issues and sub-issues natively)
- sub-issue
- issue
- issue
- epic-2
- issue
- issue
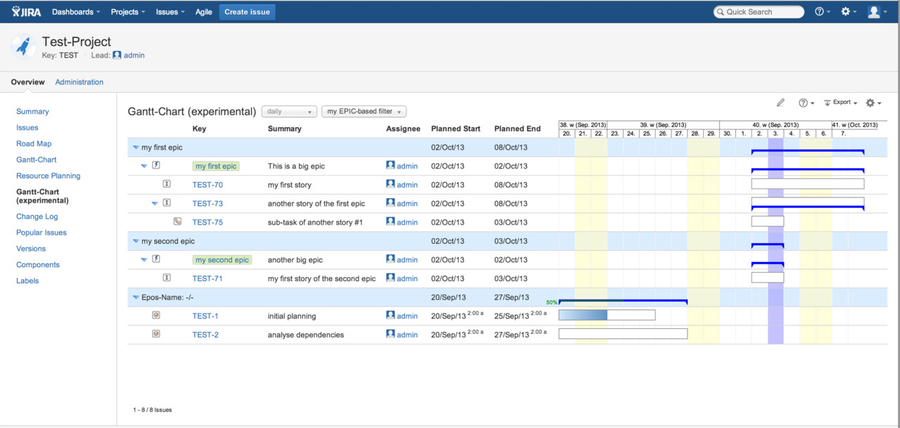
If you do not want to set up a related filter or you want to use an existing filter being consumed by yourself not having this special kind of order-by clause, you can explicitly specify the grouping: click on Gantt menu item "configure columns" and enable the option being marked in red within the screenshot below. Then select the column "epic-name" within the combo box, click on button "add" and terminate by clicking on "finish". Each time you display a Gantt-Chart using the same selection (filter, board), this configuration will be read for grouping regardless what's within the order-by clause.
Automatically update Gantt-Chart without any manual efforts, just work on your agile boards
General approach:
- Using "Jira Software", you can create issues on your backlog.
- Then, maintain your user-stories by entering estimations in form of story points.
In best case, you also assign that issues if you know, who of your team will take care about what user-story. - Now, create a sprint and assign issues to that sprint.
- Finally start that sprint.
=> in the background, the Gantt-Chart app recognizes starting of a sprint and automatically reschedules all related issues:
All unassigned issues will get a planned start date equal to the defined sprint start date. The planned end date will be calculated based on the planned start date and your provided estimated duration as described below.
Per assignee, all related issues will be scheduled in the sequence of their ranking: the first issue will start on the sprint start date, its planned end date based on planned start date plus estimated duration (see below). The next issue will get a planned start date after the prior planned end date taking non-working days and end-of-days into account.
Estimations can be done like standard Jira work logging: maintaining originally estimated effort like "2d", remaining estimation etc. Alternatively, you can estimate using story points. Doing this, you have to configure a time equivalent within your project administration (1 story point is equal to - for example - 4 working hours). In both cases, the effort will be multiplied by the related velocity, which can be specified per issue (custom field: velocity-%) or per user/assignee. A velocity of 50 (%) means, that an effort will need double time/duration. This can be used, if you have got different skills: for example, a senior acts faster (125%) than an unexperienced junior (50%) but the estimation of an issue is independent from the assignee's skills.
If you work differently: you can also enter a planned start date and original estimated effort and the planned end date will be calculated automatically.
Working agile:
- If you delete an issue being part of a sprint, all other issues of that sprint will be automatically rescheduled.
- If you move an issue within its sprint (re-ranking), all issues of that sprint will be automatically rescheduled to reflect that new order.
- If you move an issue from one sprint into another sprint, all issues of the old sprint will be rescheduled to fill up the duration of the moved issue as well as all issues of the target sprint to ensure a time sequence based on issues' rank.
- If you assign an issue to another user, it will be re-scheduled to guarantee a proper sequence of issues per assignee without timely overlapping.
- If you start a sprint, its issues will be re-scheduled starting on the sprint's effective start date.
All this happens with a small delay of about 1 minute, so that the Jira-internal lexoRank has been finished with internal reordering of the Atlassian rank field. Any re-scheduling updates the related issues' planning dates (start/end) and write a corresponding information into the issues' history. So, not just the screen of any Gantt-Chart is displaying the new date/times but also on every Jira screen containing planned start and end dates: that's full integration!